ChatGPT Mines 16 Million Reddit URLs and Cites 1.93% of Them
Ahrefs analyzed 1.4 million ChatGPT prompts and found that ChatGPT retrieves Reddit content constantly but cites it only 1.93% of the time. Reddit accounts for 67.8% of all pages ChatGPT retrieves and never credits. The practical implication: GEO strategies built around seeding Reddit threads to influence ChatGPT citations are optimizing for the one channel ChatGPT systematically hides.
The number that should embarrass every GEO slide deck
The Ahrefs study is the biggest public dataset on how ChatGPT decides what to cite: 1.4 million real ChatGPT 5.2 prompts, more than 25 million search results, and over 16 million Reddit URLs pulled through a separate Reddit retrieval channel.
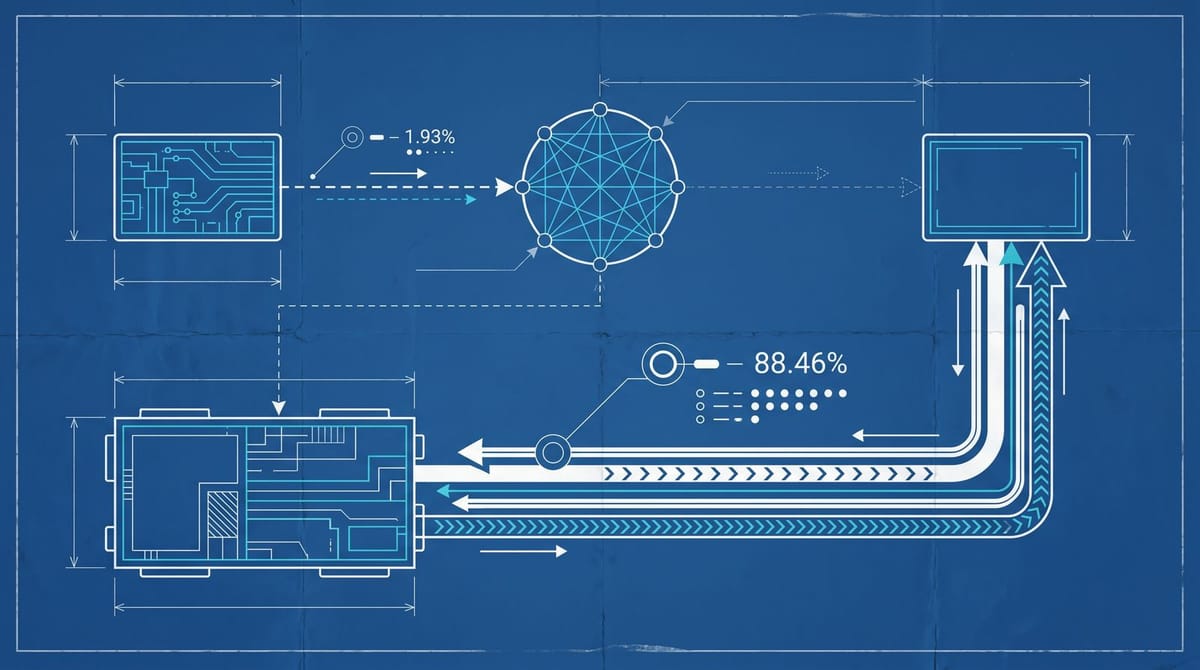
The general search index cites 88.46% of what it retrieves. Reddit sits at 1.93%. That is not a rounding difference. Those are two categorically different things happening under the hood, both called "retrieval" in the GEO tooling most brands are buying.
ChatGPT is using Reddit extensively to understand topics, gauge consensus, and build context, but it almost never gives Reddit the credit. (Ahrefs)
Search Engine Journal's writeup put the sharper version of the same point: Reddit is the source ChatGPT reads and the source it refuses to show you.
Why ChatGPT treats Reddit like a research assistant it never credits
Reddit gets its own dedicated ref_type inside ChatGPT's retrieval stack. That comes from the May 2024 data licensing deal with OpenAI, which is reportedly worth around $70 million a year to Reddit. What the deal bought OpenAI was access, not ranking signal. The model uses Reddit to shape its understanding of how humans actually talk about a product, a controversy, a drug side effect, a software workflow. It almost never surfaces that signal back into the answer as a clickable link.
In most cases I have looked at, that behavior seems intentional. A Reddit thread is a good place to learn consensus and a bad place to send a user who asked a professional question. From ChatGPT's product-safety angle, citing a random r/marketing hot take as the authoritative source on Smart Bidding would be worse than not citing anything. So the model reads it, metabolizes it, and then reaches into the general search index for a citation it can defend.
Ahrefs' methodology is worth understanding because it answers the question every GEO tool has been fudging. Researchers used open-source embeddings to compute cosine similarity between page titles and the sub-queries ChatGPT generates when it decomposes a prompt (the "fanout"). They then isolated results by ref_type, so Reddit pages were only compared against other Reddit pages and general search pages against each other. That is why the 1.93% Reddit citation rate is not a comparison artifact. The study controlled for the thing most dashboards average away.
What Reddit-first GEO strategies actually produce
A lot of the "get cited in AI" decks circulating right now are still built on the 2024 thesis that Reddit is disproportionately cited by LLMs. That thesis was accurate for a moment. Search Engine Land covered data earlier this year showing Reddit was the single most-cited domain across multiple AI systems. The problem is that the systems behave very differently, and averaging them hides the actual signal.
Semrush's citation tracking caught the split clearly. According to their most-cited-domains analysis, ChatGPT was citing Reddit in close to 60% of prompt responses in early August 2025, and the rate collapsed to roughly 10% by mid-September. Perplexity and Google AI Mode did not move the same way in that window. If you are buying a GEO tool that reports "AI visibility" as one number, you are averaging those curves together and pretending they measure one thing.
The Ahrefs study also clarifies the one way Reddit still does get cited by ChatGPT: when a Reddit page shows up inside the general web index and wins on title-to-sub-query similarity. That is a different retrieval path than the dedicated Reddit channel, and it plays by the same rules as any other page. Our piece on what makes ChatGPT cite a page spells those rules out: the title has to semantically match the sub-query ChatGPT has decomposed the prompt into, which is a very different bar than ranking on Google.
The one Reddit play that still works (and it is not on ChatGPT)
Recent tracking across commercial categories like technology and consumer electronics has seen Reddit's citation share grow even as its overall citation frequency declines. That sounds contradictory and it is not. LLMs are citing Reddit less often overall, and leaning on it more when the query is "best X for Y" or "is [product] worth it."
That pattern reads cleanly across Perplexity and Google AI Overviews, not ChatGPT. Perplexity in particular still pulls roughly half its top sources from Reddit. If your brand lives in product-consideration queries and your AI referral traffic is mostly Perplexity or Google AI Mode, Reddit seeding still has a case. If your AI referral traffic is mostly ChatGPT (which is where about 87% of AI referral volume sits across most verticals), Reddit is the wrong line item.
Where the budget should go instead
Most teams are going to overcomplicate this. The Ahrefs data points to a single-variable fix: title semantic match to ChatGPT's decomposed sub-queries. That means fewer Reddit AMAs and more of something boring. Three concrete bets to run this week:
- Take the top 20 commercial prompts in your category and run them through ChatGPT with the sources panel open. Write down which domains got cited and which got retrieved and ignored. Those two columns are your real GEO target list. Benchmark to hit: at least 5 of the 20 prompts surfacing your domain in the cited column inside 90 days.
- For every sub-question ChatGPT generates internally (the fanout queries), make sure at least one page on your domain has that sub-question roughly as its title tag. Not the H1, the title. The title was the strongest predictor of a citation in the Ahrefs dataset, and the practical version of that finding is unusually specific: rewrite your title tags as declarative answers to the sub-questions you see ChatGPT generating, not as keyword-stuffed SEO boilerplate.
- Cut the "Reddit ghostwriting" and "seed r/marketing" retainers that snuck into 2026 budgets during the 2024-era Reddit panic. Reallocate to first-party explainers with title-matched sub-queries. If you are spending more than about 15% of your GEO budget on Reddit activity and your AI referral traffic is ChatGPT-heavy, you are overpaying on the channel with the 1.93% payoff.
The part I am less sure about
One caveat worth saying out loud. The 1.93% Reddit citation rate is a February 2025 snapshot of ChatGPT 5.2 desktop only. OpenAI's citation logic shifts constantly, and the September 2025 collapse from 60% to 10% is evidence of exactly how fast. So the specific number will move, and it could drift back up if OpenAI decides a Reddit-heavier citation mix is better for user trust. What I do not see changing is the architecture: Reddit as a dedicated retrieval channel, separate from the search index, used for context far more than attribution. That is the part a Reddit-first GEO strategy keeps misreading.
If you are revising your 2026 GEO brief this week, the cheapest change you can make is to stop paying for Reddit attention you cannot convert into citations. Spend the time on the title-match work instead. It is less fun to sell and it is what the data actually supports.
Notice Me Senpai Editorial