Google's Web Bot Auth Test Leaves Most AI Agent Requests Unsigned
Google started testing Web Bot Auth on May 5, 2026, an experimental protocol that uses HTTP Message Signatures (RFC 9421) to cryptographically verify requests from AI agents. Only a subset of Google-Agent traffic is signed today, and Google still tells publishers to keep falling back to IP, reverse DNS, and user-agent strings. The signature proves who is asking. It does not say whether you should serve, block, or bill differently.
What Web Bot Auth actually does
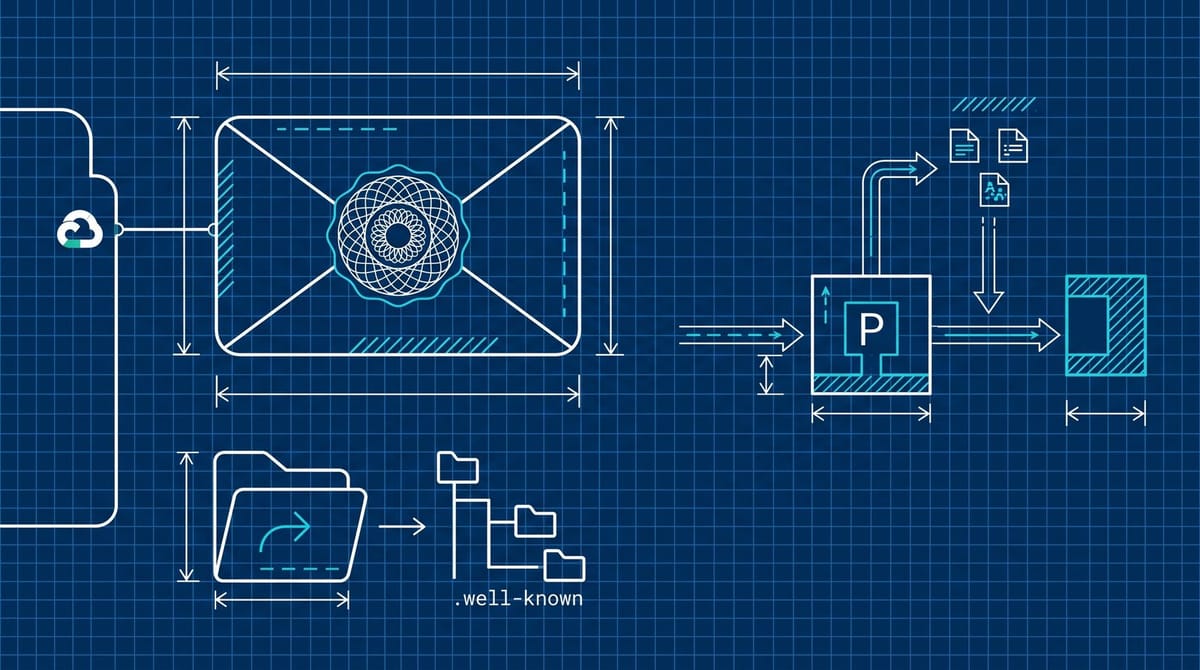
A signing bot publishes a public key in a .well-known directory on a domain it controls, holds the private key, and signs each outgoing request. The request carries two extra headers: Signature-Input (which fields are signed and how) and Signature-Agent (which key directory to fetch). Google's signed traffic identifies as g="https://agent.bot.goog". The server fetches public keys from https://agent.bot.goog/.well-known/http-message-signatures-directory, caches them per Cache-Control, and verifies per the IETF draft authored by Thibault Meunier (Cloudflare) and Sandor Major (Google). The whole protocol is documented on Google's crawlers and fetchers page.
Cloudflare and Google co-authored the spec. The reference implementation lives on Cloudflare's GitHub. The IETF Web Bot Auth Working Group was chartered earlier this year, and Akamai and Amazon's AgentCore Browser already ship support, per Search Engine Land's coverage. The architecture is explicitly an HTTP-layer-only thing. No TLS changes, no transport changes, no client cert dance. Whether your CDN is preserving the signature headers when it forwards to your origin is the first question worth asking, because most reverse-proxy defaults strip headers they do not recognize.
The keys themselves are Ed25519 in the example payload, with nbf (not before) and exp timestamps that effectively force key rotation. That detail matters because it means a long-cached public key will eventually fail validation. If your verification stack does not respect the Cache-Control directive on the directory fetch, you will start dropping signed requests on day one of the rotation window and have a hard time figuring out why.
The two-tier problem nobody is talking about
Here is what is actually broken about today's rollout. Google says, in its own docs, that not all Google user agents are using Web Bot Auth, and that even participating agents do not sign every request. So one Project Mariner session can hit your site five times in a minute and produce five different verification states: signed, unsigned, signed-with-cached-key, signed-with-stale-key, signed-with-key-fetch-failure. Your bot management config does not currently have a row for any of those.
Most rules I have seen in the wild treat user-agent string plus reverse DNS as a binary "this is Google or it isn't." Web Bot Auth introduces a third state, a fourth, and an unhappy fifth. There is no consensus yet on which response code, log treatment, or billing event each one earns. The Search Engine Journal piece that broke this buries the operational point: Google is shipping the cryptography first and the policy never. That is a normal way to roll out a protocol. It is an unusual position to put publishers and ad servers in.
Why your robots.txt and bot rules need a pass this month
The bigger question hanging over every publisher right now is whether Google-Agent traffic should be treated like Googlebot, like a paid AI scraper, or like a user. The signature does not answer that question. It only proves provenance. From what I have seen, three lanes are emerging:
- Lane 1. Signed agent traffic served the same as a human visit, no robots.txt block, no rate limit, no special accounting. This is the default if you do nothing.
- Lane 2. Signed agent traffic served but logged separately, with the signature state stored, so you can renegotiate licensing later the way the AP and Reuters did with OpenAI.
- Lane 3. Signed agent traffic blocked or rate-limited until your legal team has a position on whether it is a "use" you charge for.
The default option is the dangerous one. Microsoft already announced last week that Bing's billion monthly users are being counted as humans only, with agents excluded from the headline metric. We covered the framing problem in our note on Bing's human-only traffic. Google's signature now hands you the data to do the same separation. Most analytics stacks are not splitting it out, and Lane 1 is what they fall into without a config change.
The 20-minute audit worth running this week
You can stop reading the rest of this and do this part now if you skip nothing else.
- Grep last week's access logs for the
Signature-Agentheader. If your CDN or load balancer is stripping it before it reaches your origin, your edge config is the first fix. No header, no policy possible. - Add
g="https://agent.bot.goog"to your bot management ruleset as a distinct category, separate from Googlebot and separate from generic user-triggered traffic. - Decide a Lane 1 / Lane 2 / Lane 3 policy per content type. Editorial commentary, evergreen guides, and gated lead-gen probably should not all be treated the same.
- Send a test fetch with a forged
Signature-Agentheader against your own site and verify the stack rejects it. If your code returns 200 to anything that just claims to be agent.bot.goog without verifying the signature, the audit ends there until that is fixed. - If you sell ad inventory, push your SSP to expose the signature state in the bid request. Right now, agent traffic is being valued like human traffic, and nobody is going to flag the discrepancy for you.
The whole audit is roughly 20 minutes if your engineering team already knows where the access logs live, and half a day if they do not. Either way, it is shorter than the meeting where you explain why agent traffic took a chunk of your inventory at full CPM.
What I think actually plays out
This is the part I am least confident in. From what I have seen, the IETF group will land a best-current-practice document inside six months, and Cloudflare's reference implementation will become the de facto stack because nobody is going to write a competing one. The harder fight is policy. Akamai already published a piece arguing Web Bot Auth lets you redefine trust on your terms, which is corporate-speak for "raise prices on signed traffic." That fight has not started in the open yet. It will.
If you operate a publisher site or a programmatic SSP, treat the next two months as your one-time chance to set defaults before the standard hardens around whatever everyone happens to be doing. Defaults set during experimental phases of a protocol are stickier than the spec itself. The robots.txt convention from 1994 still binds Google in 2026, and Google wrote that one too.
The piece nobody is admitting
Signed-but-unwanted is going to be the most common state of all. Plenty of legitimately Google-signed agents will hit pages that publishers do not want them to scrape, summarize, or quote. The signature gives you the certainty to say no. Whether saying no is commercially smart, when Google's AI Overviews already pull from the same content with no signature at all, is the question I do not see anyone answering well yet. I do not have a strong position on it. Anyone who does, this early, probably has not done the math on what blocking actually costs them.
What I am confident about is narrower. The shape of your bot policy in May 2026 is the shape Google's lawyers will quote back at you in 2028 when they argue you consented to something. Make sure that shape is one you actually want.
Notice Me Senpai Editorial