Cloudflare's Project Think Lands 48 Hours After OpenAI's Sandbox SDK
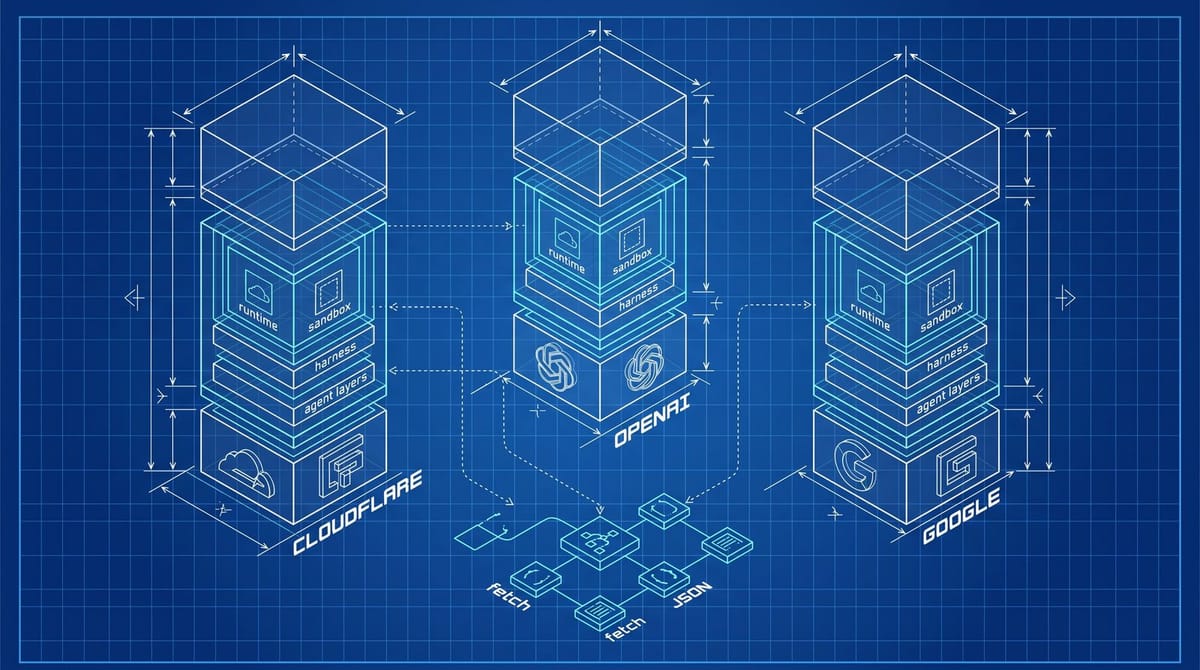
Cloudflare shipped Project Think on April 13, 2026, and OpenAI shipped a sandbox-native Agents SDK two days later on April 15. Both are runtime infrastructure for AI agents to fetch, execute, and persist work across tasks, not models that read your site better. The SEO bar moved from machine-readable text to machine-callable endpoints, and most sites still ship neither.
What actually shipped in eight days
Three things landed in the same eight-day window in April. On April 7, Sundar Pichai told the Cheeky Pint podcast that Google Search would become an "agent manager" coordinating "many threads running" against the open web, covered at Search Engine Land and Search Engine Journal. On April 13, Cloudflare expanded its Agent Cloud and rolled out Project Think, a stack of durable execution, sub-agents, persistent sessions, and sandboxed code execution. Two days later, OpenAI updated its Agents SDK with native sandbox execution, a model-native harness, and a Manifest abstraction for mounting workspaces from S3, GCS, Azure Blob, or Cloudflare R2.
That's three competing answers to the same question, shipped before most marketing teams had finished their AI Overviews audit. SEJ's Duane Forrester framed it as the agent runtime wars, which sounds dramatic until you notice that Cloudflare alone now owns the runtime, the inference routing layer, the vector index, and the email sending channel for agents. It's a substrate underneath whichever model wins.
The runtime is the layer agents pay rent on
Help Net Security's coverage of the OpenAI release described the new harness as letting agents "inspect files, run commands, edit code, and work on long-horizon tasks within controlled sandbox environments." The interesting part is the list of supported sandboxes, which now includes Blaxel, Cloudflare, Daytona, E2B, Modal, Runloop, and Vercel. OpenAI is not picking one. It's deferring to whichever runtime the developer already pays.
That mirrors Cloudflare's pitch in reverse. SiliconANGLE's coverage of Project Think framed Cloudflare as moving agents from "experimental demos on local laptops to robust, production-grade workloads." The execution ladder Cloudflare published runs workspace, isolate, npm, browser, sandbox, with each rung addressable as a primitive. Workers get fibers that survive server restarts. Sessions get tree-structured forking and full-text search.
If you've spent the last 18 months optimizing pages for AI Overviews citations, the framing shift hurts a little. The model layer is converging. The runtime layer is the new pricing surface. And the runtime is what decides whether an agent can finish a task on your site or bounces and tries a competitor.
Where this leaves your schema and your robots.txt
Schema markup, JSON-LD, Open Graph, the whole machine-readable text layer, those are still required. They are no longer enough. Three protocol shifts are doing work that schema used to handle alone:
- MCP (Model Context Protocol). Backlinko's protocol roundup notes there are now more than 10K MCP servers as of early 2026, making it the de facto standard for agent-to-tool connectivity. If your site exposes one, agents can query inventory, prices, and availability through a typed interface instead of scraping HTML.
- WebMCP. Google and Microsoft co-proposed the spec, the W3C Community Group is incubating it, and Chrome shipped an early preview in February 2026. It is the browser-side companion to MCP and is what the "many threads" Pichai referenced will likely talk to.
- UCP (Universal Commerce Protocol). Google and Shopify co-developed it with 20+ launch partners. When AI Mode tries to actually buy something, UCP is the layer that decides whether your brand is in the conversation or out of it.
Each of those is an API and auth problem before it is anything else. Robots.txt now does less work than your authentication scoping. Verified bot signing is a separate negotiation; we covered Google's Web Bot Auth test in March and most agent traffic still hits sites unsigned. From what I've seen, the shift in priority feels real, even if no one has published clean adoption numbers yet.
The agent-readiness audit that runs in 30 minutes
If you only have an hour this week to react, do these three things in order. They map to the three runtime test capabilities the SEJ piece flagged, and they're worth keeping verbatim.
1. Hit your top three product or article URLs with curl and headers stripped. What renders without JavaScript? If your pricing, hours, inventory, or core editorial content needs the JS bundle to appear, the agent gets blank text. The fix isn't necessarily SSR everything. It's exposing the same data through a JSON endpoint you can advertise via a .well-known/ discovery file or a meta link tag.
2. Test scoped session continuity. Pick a multi-step task on your site (filter inventory, then add to cart, then check shipping). Ask an agent SDK to run it twice with one auth token. If your auth is cookie-only and burns the session on a refresh, you've capped your agent compatibility before content even matters. OpenAI's Agents SDK and Cloudflare Agents both expect persistent token-scoped state.
3. Ship one MCP endpoint or one signed JSON feed. Doesn't need to be the whole catalog. One named dataset (returns policy, pricing tiers, FAQ corpus, latest articles) exposed at a stable URL with a versioned schema buys you AI Mode and Gemini Enterprise eligibility. The Cloudflare press release on Agent Cloud explicitly calls out "production-grade workloads" as the bar, which is a polite way to say one endpoint nobody updates is worse than no endpoint.
Anything beyond those three is upside.
Why "agent manager" isn't a metaphor
Pichai's framing on the Cheeky Pint podcast deserves a second look. He said Search would coordinate "many threads running" doing "information-seeking queries" that are "agentic." The Next Web summarized the Cloud Next 2026 keynote where he gave the same talk on a bigger stage: $240B backlog, 750M Gemini users, $175-185B in planned capex for 2026. The thing being capitalized at that scale isn't "answer the query." It's "run the agent that runs the queries that complete the task."
In that world, your site is one of the n threads. If your thread crashes when refreshed, returns blank under fetch, or 401s on a second call, the agent skips you. There's no recovery on the user side because the user is two layers up the stack and was never going to see a SERP for that intent.
Personally, I think most teams will overcomplicate this and try to MCP-ify everything before they fix the structured-data baseline. That's backwards. Schema first. Endpoints second. Sandbox-friendly auth third. The order matters because the runtimes still fall back to text and JSON-LD when they can't find anything richer, so the floor still pays.
What I'd ship this month and what I'd skip
If your site does e-commerce, get on the UCP partner list before "20+ partners" becomes "200." Shopify is the wedge there; if you're on Shopify, half the work is checking a box.
If your site is content-led (publishers, agencies, B2B blogs), skip building your own MCP server for now and ship two things instead. First, a .well-known/ai.json file that lists your stable JSON endpoints and rate limits. Second, server-rendered article bodies behind clean URLs without ?utm litter. We covered the AI traffic referrer-strip problem last month and the takeaway holds: agents that can't trace back to you don't count, no matter how cleanly you get cited.
Skip building a custom agent-side scraper. The runtimes are converging fast enough that a tool you ship in May will probably outlive its API by July. Better to spend that engineering hour on a JSON endpoint your CMS can update without a deploy.
The actual question to answer this quarter isn't which model wins. It's which runtime your site already passes a clean fetch from. If it's none of them, that's the audit task.
Notice Me Senpai Editorial