Google-Agent Ignores robots.txt. The Only Real Block Is at Your Firewall.
Google launched Google-Agent on March 20, 2026, a new user agent for AI systems running on Google infrastructure that browse pages on behalf of human users. Unlike Googlebot, it ignores robots.txt because Google classifies it as a user-triggered fetcher, meaning the only reliable way to block it is server-side authentication or a firewall rule against Google's published IP ranges.
What Google-Agent actually is, and what it is not
This is the part most coverage gets wrong on the first read. Google-Agent is not a new crawler. It does not replace Googlebot, it does not index pages for search, and it does not feed AI Overviews. According to Google's own documentation on user-triggered fetchers, Google-Agent only shows up when a human asks an AI assistant to fetch or interact with a specific URL. Someone asks Gemini to compare two products. Someone uses an agentic browser feature to fill a form. The visit happens on behalf of that person, not as part of any Google index.
The user agent string contains compatible; Google-Agent. Google is rolling it out over a few weeks, so log volume will ramp gradually rather than appear as a single spike.
If you were assuming this was a Googlebot replacement and started to panic about crawl budget, you can stop. Googlebot still runs separately. Google-Agent traffic is sporadic by definition: it shows up when a user prompt triggers a fetch, and it tends to hit deep pages (product detail, pricing, checkout flows) rather than the homepage and category trees Googlebot lives on.
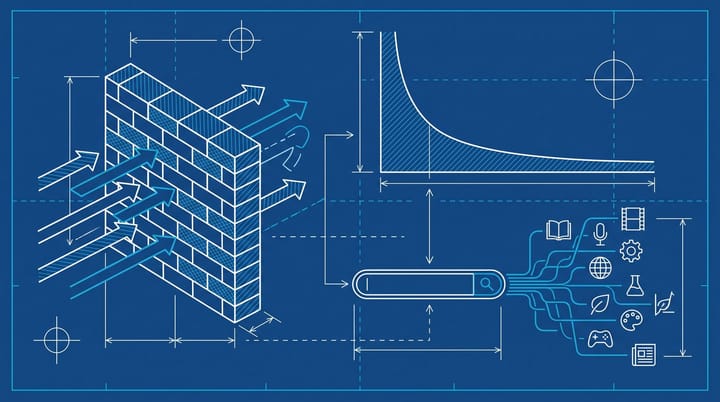
Why robots.txt does nothing, and what works instead
Google's user-triggered fetcher policy is explicit on this point: because the fetch was requested by a person, these agents generally ignore robots.txt rules. The legal-style framing is that it sits closer to a browser visit than a crawl, so the same access conventions apply.
For SEO teams who built their whole "AI agent control" plan around a Disallow line, this is the policy moving the goalposts. ChatGPT-User and Claude-User still respect robots.txt. Google has decided its own user-triggered tier does not have to.
The fallback is real but more work:
- IP-based blocking. Google publishes the IP ranges for user-triggered fetchers in a JSON file linked from the user-triggered fetchers documentation. Add those to your CDN or WAF rule set. From what I have seen, most sites that already manage Googlebot allowlists at the WAF level can extend the same policy in under an hour, and the harder lift is anyone who has been letting Cloudflare's default "block AI bots" toggle do the work without auditing it.
- Server-side authentication. Any page behind a real auth wall stays behind a real auth wall. Google-Agent will not get past it any more than a human user would without credentials.
- Reverse DNS verification. If you want to allow it but log it cleanly, do a reverse DNS lookup on the request IP followed by forward confirmation. It is the same pattern Google recommends for verifying Googlebot.
Worth saying out loud: there is no shame in choosing to allow Google-Agent everywhere by default. The bigger risk for most commerce sites is silently breaking an agent flow on a product page they want to be discoverable inside Gemini answers. PPC Land's coverage of the rollout made the same point: the access decision is now a per-path call, not a site-wide one.
Web Bot Auth is the part that will matter in six months
Google is also experimenting with Web Bot Auth, an IETF draft cryptographic protocol that lets agents sign their requests so a site can verify them without doing reverse DNS gymnastics on every hit. The identifier Google is using is https://agent.bot.goog.
This is the piece that has more long-term weight than the robots.txt change. If Web Bot Auth becomes the standard, every reputable AI agent will sign its traffic, and the line between "legitimate AI fetcher" and "scraper pretending to be one" becomes a cryptographic check rather than a header parse. The current bot-detection vendors built their pricing around the header parse, so you can expect the messaging from DataDome, Cloudflare Bot Management, and similar to shift over the next two quarters.
I think most teams will overcomplicate this. You do not need to ship Web Bot Auth verification yourself this month. You do need to flag it as something your CDN or WAF vendor should be supporting natively by Q3, and to push them on a timeline if they go quiet about it. The vendors that already work with Cloudflare's bot management layer are likely to ship first, smaller niche providers are likely to be six months behind, and that gap will matter for any team handling enough traffic that bot management is a line item.
Your analytics will not show this traffic, and that is the real story
This is the part that does not get said clearly enough. Google-Agent visits show up in your server logs. They do not show up cleanly in GA4. GA4's recently launched AI Assistant channel only catches sessions where the referrer header matches a recognized AI assistant, and Google-Agent does not behave like a referring source. It behaves like a headless visit coming from a Google IP range.
We covered the underlying gap in our piece on GA4's AI Assistants channel and the 70.6% it cannot actually see, and Google-Agent is the practical example of that limitation playing out. If you are reporting AI-driven traffic out of GA4 only, you are missing the chunk that comes through Google's own infrastructure, and that chunk is likely to grow faster than the referrer-based portion as Gemini adds more agentic browsing features over the rest of the year.
The cleaner answer is to pull server log data into a query layer (BigQuery, Snowflake, or even an S3-backed Athena setup) and segment by user agent. That gives you Google-Agent volume by URL, request timing, and conversion path when you join it back to your transaction tables. On paper, it sounds like a step back into 2014. In practice, it is currently the only way to see this layer of traffic with any fidelity, and the same query will work for ChatGPT-User and Claude-User without rewriting it.
The audit nobody scheduled this week
If I had thirty minutes, this is roughly the order I would do it. Pull last week's server logs and grep for Google-Agent. Map which URLs it hit and whether any of those URLs are behind robots.txt rules you assumed were enforcement. Check your WAF for a default-deny rule on uncategorized Google IPs that could silently be blocking legitimate Google-Agent traffic, which is the inverse problem to the one most people are worried about. Then add a server-log query to whatever dashboard your team checks weekly, so this becomes a tracked stream instead of a one-time look.
The honest read on Google-Agent is that it is not the threat people are scrambling to position it as. It is a small piece of plumbing that exposes how much SEO and analytics tooling was quietly built on the assumption that bots either respect robots.txt or get caught by referrer detection. Both assumptions are now half-true, and the gap between them is exactly where Google's agent traffic lives.
Reading server logs feels like a step back into 2014, and most analytics teams have spent the last five years arguing for moving away from them. The small irony of Google-Agent is that it is the cleanest reason to keep one tab on them open.
— Notice Me Senpai Editorial