Natural Language Is Breaking AI Ad Agents (and the Fix Is Boring)
If you hand a campaign brief to four different people at an agency, you get four slightly different interpretations. That is normal. It is also manageable, because humans catch the drift in review meetings and email threads before anything ships.
Now imagine the same brief passed between four AI agents in a programmatic supply chain. Each one reinterprets the language probabilistically, at machine speed, with no review meeting. The drift does not get caught. It compounds.
Katie Shell, Associate Product Manager at IAB Tech Lab, published a paper that frames this as a systematic failure mode, not an edge case. And the fix she is proposing is not more sophisticated AI. It is integer lookup tables.
How "No Adult Content" Becomes a Wine Review
Shell's paper walks through a scenario that, if you have managed brand safety at any scale, probably feels familiar even without AI in the mix.
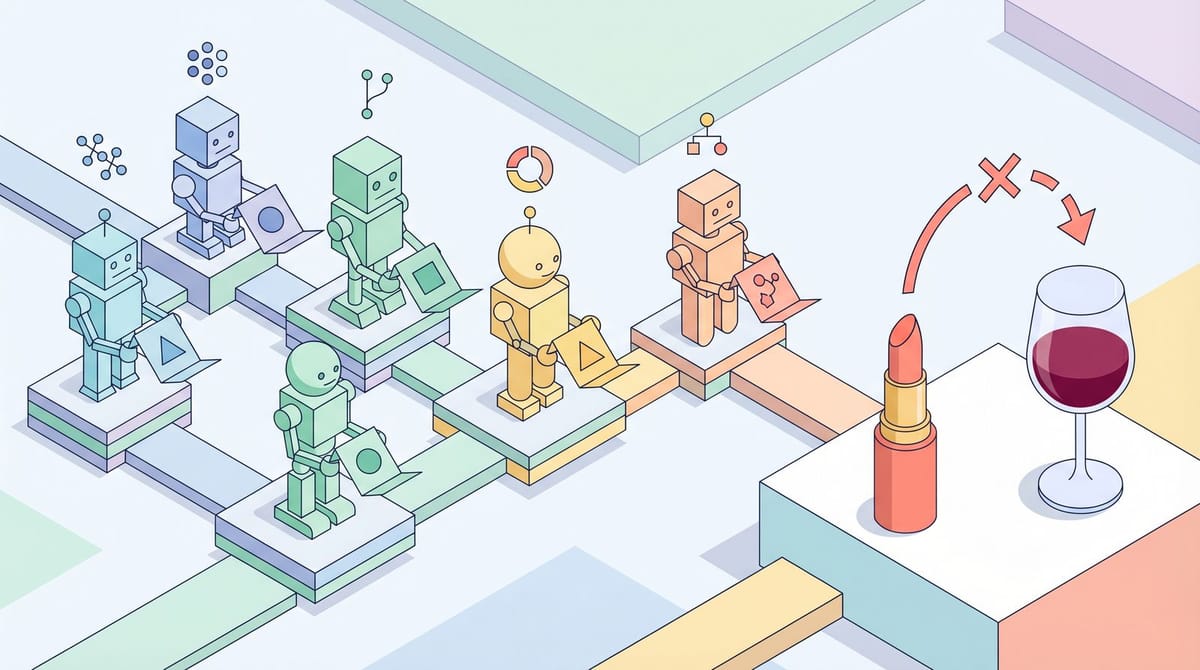
A buyer agent receives a brief: "lifestyle content targeting women 21-45 interested in beauty, no adult content." Straightforward enough. But when the buyer agent passes this to a seller agent, the language shifts. "Beauty" drifts toward "wellness." "Wellness" gets interpreted as fitness-focused content. Neither agent is technically wrong. They are doing what language models do: predicting likely completions based on training data, not looking things up.
As Shell puts it: "LLMs generate outputs as probability distributions over language. They do not look up facts, they predict likely completions."
Across four or more hops in a supply chain, "no adult content" gets reinterpreted loosely enough that a lipstick brand ends up next to a wine review page. Not pornography, obviously. But alcohol content the brand explicitly wanted to avoid. It happened because every agent in the chain applied its own probabilistic spin to plain English.
Think of it as the telephone game, except the players are faster and more confident than humans, and nobody is around to say "wait, that is not what the brief said."
1,500 Integer IDs That Replace Interpretation
IAB Tech Lab maintains three standardized taxonomies that assign integer IDs to categories. Content Taxonomy v3.1 now covers over 1,500 categories (up from roughly 400 in v2.x). "Automotive > Green Vehicles" is ID 22. "Food & Drink > Cooking" is ID 357. The Ad Product Taxonomy labels what is being advertised: Alcohol > Wine is ID 1007. The Audience Taxonomy standardizes demographics: Female is ID 49, Age Range 30-34 is ID 6.
The practical difference is boolean matching instead of language interpretation. That same lipstick campaign, expressed in taxonomy IDs, transmits as: target Female [49], ages 21-44 [IDs 4-8], blocklist Alcohol [1002], Cannabis [1049], Adult Products [1001]. Every node in the supply chain performs exact matching. There is nothing to reinterpret.
It is boring. That is sort of the point.
I think a lot of the conversation around agentic advertising has focused on how sophisticated the agents are, how good their natural language understanding is, how much they can automate. Some of that is genuinely impressive. But Shell's argument, which I find pretty convincing, is that the supply chain problem is not about making agents smarter. It is about removing the need for interpretation entirely at the machine-to-machine layer.
The Infrastructure Nobody Expected This Fast
This is not theoretical. Several pieces shipped in Q1 2026.
Kochava opened StationOne to public beta on March 25, the first accessible sandbox for testing AAMP-compliant (Agentic Advertising Management Protocols) workflows. It includes 19 specialized agentic skills across 8 functional areas, all running through IAB Tech Lab's reference MCP server built on the OpenDirect 2.1 spec. If you have been wondering what agentic ad buying looks like in practice, this is the first place you can try it without risking real spend.
Mixpeek donated an open-source taxonomy mapper in February that reduced Content Taxonomy 2.x to 3.1 migration from weeks of manual work to seconds. It runs locally, uses TF-IDF and BM25 scoring plus optional LLM re-ranking, and exports results ready for OpenRTB integration.
IAB Tech Lab's own agentic roadmap, published in January, integrates established standards like OpenRTB and AdCOM with modern protocols including Model Context Protocol (MCP), Agent2Agent (A2A), and gRPC. The Agent Registry, launched March 1, already has 10 participating companies and requires taxonomy category selection at registration.
On paper, that sounds like typical standards-body progress. Slow, committee-driven, lots of acronyms. And in some ways it is. But the speed here is notable. Roadmap to working sandbox in under three months is fast by IAB standards. Someone over there seems to understand that the window for setting these defaults is narrow.
Where Integers Run Out
I do not want to oversell this, because it does not solve everything.
Taxonomies update slower than the internet creates new content categories. AI-generated video formats, creator economy niches, whatever emerges next month: these fall into gaps that take quarters to close. Shell acknowledges this directly, and it is worth taking seriously. If your brand operates in an emerging category that does not map cleanly to one of the 1,500 content IDs, you are back to some form of language-based targeting whether you want to be or not.
There is also a self-tagging problem. Publishers assign their own taxonomy IDs, which creates the same incentive misalignment that has plagued contextual targeting forever. A site that tags itself as "Business News" when it is really "Celebrity Gossip with a Finance Section" is not a new problem, but it is one that deterministic matching does not fix. Verification standards remain, from what I can tell, largely unresolved.
And honestly, some targeting requirements are just more natural as language. "Premium editorial feel" or "brand-safe but not boring" are real buyer preferences that do not map to integer IDs. I would estimate roughly 15-20% of the targeting criteria in any sophisticated campaign brief still falls into this gap. That number will shrink as taxonomies expand, but probably not as fast as the standards bodies are hoping.
Three Questions Your DSP Probably Cannot Answer Yet
If you are a media buyer or agency evaluating agentic tools, there are a few things worth checking now rather than later.
Ask your DSP or programmatic vendor which taxonomy version they support. Content Taxonomy 3.1 has nearly four times the categories of 2.x. If your vendor is still on 2.x, the precision gains from structured IDs are significantly reduced. This is a simple question that reveals a lot about how seriously they are treating the infrastructure layer.
Check whether your agency's AI tools pass taxonomy IDs between agents or translate everything to natural language first. Adform's Audience Discovery Agent, for example, accepts natural language prompts but maps them to IAB Audience Taxonomy IDs before executing. That is the right architecture. If your tool chain cannot explain what happens at the agent-to-agent layer, that is a problem worth flagging before you start running real budget through it.
We covered a related standardization fight recently: The AI Ad Market Split Three Ways and Nobody Agrees What a Conversion Is. The conversion measurement debate and the taxonomy problem share the same root cause. Everyone built their AI tools before agreeing on a common language. Taxonomy has a head start because IAB Tech Lab has maintained these vocabularies for years. Conversion measurement has nothing comparable yet.
The unsexy truth about agentic advertising is that the agents themselves probably are not the hard part. Making them understand each other without playing telephone with your budget: that is the actual engineering problem. And right now, the best answer anyone has is a lookup table with 1,500 rows.
By Notice Me Senpai Editorial


