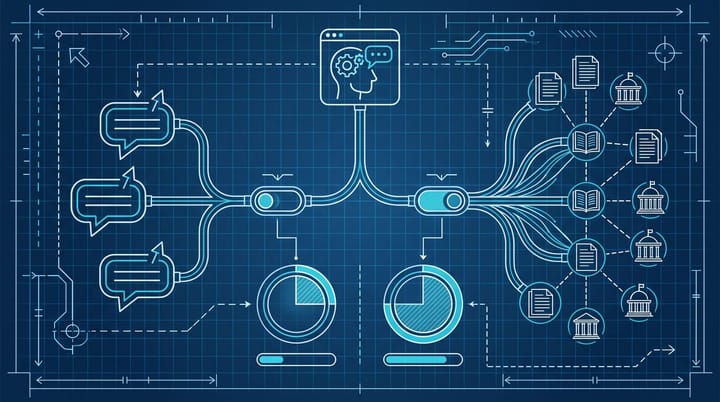
Omniscient Found 48% of AI Brand Citations Live Off Your Site

Omniscient Digital analyzed 23,387 citations across 240 branded prompts and found 48% came from earned media, 30% from commercial brand content, and just 23% from owned channels. When ChatGPT, Perplexity, or Claude name a brand, more than three-quarters of the supporting evidence sits on sites the brand doesn't control. Most AEO audits still inspect the 23%.
AI runs two filters. Your audit is checking the second one.
The Search Engine Land piece from Maryanna Franco introduces a useful split: qualification (can an AI identify and associate your brand?) and selection (will it confidently recommend you?). The two thresholds run in sequence, and almost every AEO audit I've reviewed in the last year is built around selection signals. Schema markup, snippet structure, header hierarchy, FAQ blocks. Things you change on the page and re-test in a week.
Qualification doesn't work like that. It's a slower, messier function of how many independent sources mention your brand, in what context, with what consistency. If the model can't confidently answer "what is this brand and what does it do," nothing on your site is going to push you into the recommendation set. You're not being filtered out of the answer. You never made it into the candidate pool.
48% of the answer lives somewhere you don't control
The Omniscient Digital study is the cleanest number I've seen on this. They imported 240 unique prompts (each containing a specific brand) into Peec AI, ran them across multiple LLMs, and graded each of the 23,387 returned citations. Three buckets:
- 48% earned media: news coverage, podcasts, industry roundups, third-party reviews, Reddit threads, Wikipedia
- 30% commercial brand content: comparison sites, listicles, affiliate review pages, "best of" content
- 23% owned: your site, your About page, your blog
That's an upper bound on what your on-page work can do. Even if your owned content is perfectly crawlable and schema-correct, you're touching less than a quarter of what AI uses to describe you. The Otterly Citations Report makes the same point from a different angle, by mapping where citations come from in over a million AI answers: Reddit, Wikipedia, and news dominate ChatGPT citations specifically, and Perplexity pulls roughly 16.9% of its citations from Reddit and community forums.
These two studies don't say schema is useless. They say the math has a ceiling, and most brands haven't done the work that moves the rest.
The site work that does matter is depressingly small
I want to be careful here, because the schema-doesn't-matter take is overcooked at this point. The on-page checklist that does seem to move things is short and not new:
- Brand name consistency. Same string everywhere, including in the H1 of your About page. If you trade as "Acme Co" but the legal entity is "Acme Industries Inc" and the LinkedIn profile says "Acme," you're forcing the model to disambiguate at exactly the moment it's deciding whether to qualify you.
- A factual, structured About page that answers five questions a model would ask: who, what, who for, where, since when.
- Organization schema with sameAs properties pointing to every authoritative profile the brand owns. This is the part that wires your owned data into Google's Knowledge Graph and, downstream, into the LLM training corpora that crib from it.
That's it. Three things. They probably take an afternoon. After that, more on-page work has diminishing returns until the off-page reputation graph catches up. We covered this from a slightly different angle in the delegation boundary piece: when an AI doesn't trust the brand entity, no amount of schema fixes the citation.
What I see most teams skip is the sameAs property. It costs nothing and it's the single most direct way to tell an entity-resolution system "this Twitter account, this LinkedIn page, this Crunchbase entry, and this Wikipedia stub are the same brand as the company on this domain." If the model can't draw that line, every signal on every one of those profiles bounces.
The classic failure mode I see is a brand with three different display names across LinkedIn, Crunchbase, and the legal documents on its careers page. From the model's point of view, that's three weakly-supported entities, not one strongly-supported one. The brand is splitting its own reputation graph across separate buckets, and then wondering why the AI doesn't recognize it. Fixing that is closer to a half-day of editing profile fields than a quarter-long SEO project.
A 24-hour audit that looks at the right 77%
Here's the rough order I'd run it in if I had a day:
Hour 1-2. Ask the model directly. Send three queries to ChatGPT, Perplexity, and Claude:
- "Who is [your brand]?"
- "What does [your brand] do?"
- "Best [your category] for [your target customer]?"
Note where the model gets confident, where it hedges, and where it returns a competitor. If query 3 returns competitors and not you, the failure is at selection. If query 1 returns "I don't have specific information about that brand" or wrong information, the failure is at qualification, and you're at least one rung lower than you thought.
Hour 2-4. Map the earned media gap. Run your brand name through Google with site filters for: reddit.com, Wikipedia, your top three trade publications, your top three podcast platforms. Count the independent mentions in the last 18 months. Below roughly 10, you have a qualification problem that no schema fix is going to touch. The Wikipedia citation data we covered last week is the cleanest example of why one of those entries (the Wikipedia stub) is disproportionately load-bearing.
Hour 4-6. Fix the three on-page things. Brand string consistency, About page, sameAs schema. Ship it.
Hour 6 and beyond. Start the PR work. A podcast appearance, a contributed piece in a trade publication, an industry survey response, anything that produces a third-party page where the brand name and the brand's actual category sit together in a sentence. Three of those per quarter, sustained, do more than another quarter of schema audits. From what I've seen, podcasts in particular are still mispriced, since transcripts get indexed and the brand-category co-mention is exactly what entity resolution is looking for.
This is not glamorous and it's not fast. It's also probably the only thing that moves the needle.
What the Maryanna rebrand quietly proved (and what it didn't)
Franco's piece includes a personal case study: she rebranded from "Mariana" to "Maryanna" and watched the AI surfaces update. Search engines re-indexed her in 7 days. LLMs caught up in 10. That's the part that gets cited, but I think the more interesting read is the gap.
A three-day delta between search and LLMs is small enough that the answer is probably not retraining. It's more likely that the LLMs are pulling fresh signal from the same corroborating sources Google is, and the lag is just how long it takes for those sources (LinkedIn, podcast feeds, About pages) to consistently use the new name. Which lines up with everything else in the data: AI's view of your brand updates roughly as fast as the third-party world updates its view of your brand. The brand doesn't own the timeline.
I think the right way to read all of this is that AEO and SEO aren't going to converge on technical work. They're going to converge on something closer to old-fashioned PR with an entity-resolution mindset bolted on. Where you spend your hours starts mattering more than which tool generated your schema. A digital PR coordinator with a podcast outreach habit is probably worth more to AI visibility than a third schema specialist. The 23% on your site is necessary. It's just nowhere near sufficient.